Tools portal
The CSDMS software engineers create tools to help CSDMS members couple and run models.
BMI Builder

The BMI Builder helps developers build a Basic Model Interface for their model by generating template source code which is then customized by the user for their particular model. Users provide some basic metadata for their model (such as names of input and output items, units, etc.) to the bmi builder which then creates creates BMI implementation files in their language of choice. The user then go through these file of files and implements the labeled sections.
Links
- Source code on GitHub
- Documentation on how to use the BMI Builder is provided on GitHub in the read.me file
BMI Tester
The BMI Tester is a Python package that provides command-line utilities for testing Python classes that implement the Basic Model Interface (BMI). BMI Tester also provides a Python interface to the tester that allows users to run tests programmatically. The package is easily extendable so that new tests can be added to the suite.
Links
Standard Names registry
The Standard Names registry is a Python library for working with CSDMS Standard Names.
The CSDMS Standard Names provide a comprehensive set of naming rules and patterns that are not specific to any particular modeling domain. They were also designed to have many other nice features such as parsability and natural alphabetical grouping. CSDMS Standard Names always consist of an object part and a quantity/attribute part and the quantity part may also have an operation prefix which can consist of multiple operations.
standard_names is a Python package to define, query, operate, and manipulate CSDMS Standard Names. It is distributed with a comprehensive list of the currently defined Standard Names.
The standard_names package consists of two basic classes:
- StandardName: a single name
- NamesRegistry: a collection of names.
The standard_names package has a complete set of unit tests that are continually tested on Mac, Linux, and Windows. It is distributed both as source code and as Anaconda packages from Anaconda Cloud.
Links
- Documentation for the standard_names package
- Source code
- The current Standard Names Registry on GitHub
WMT
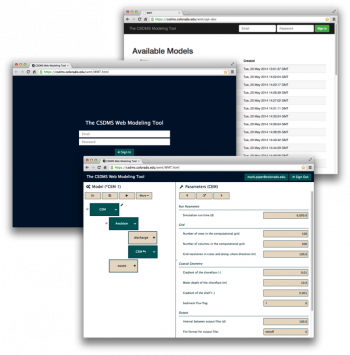
The CSDMS Web Modeling Tool, WMT, is a web application that allows users on a desktop, laptop or tablet computer to build and run standalone or coupled Earth surface dynamics models on a supercomputer.
With WMT, users can:
- Design a model from a set of CSDMS components
- Edit model parameters
- Save models to a web-accessible server
- Share saved models with the community
- Submit model runs to an HPC system
- Download simulation results
The following components are currently available in WMT.
To see how you can use WMT to configure and run a standalone or a coupled model on the web, check out the WMT tutorial, or jump right into using WMT at https://csdms.colorado.edu/wmt.
For more information on WMT, including links to its documentation and its source code repositories, please see the CSDMS Web Modeling Tool wiki page.
Dakotathon

Dakota is a software toolkit developed at Sandia National Laboratories that provides an interface between models and a library of analysis methods, including support for sensitivity analysis, uncertainty quantification, optimization, and calibration techniques. Dakota is a powerful tool, but its learning curve is steep: the user not only must understand the structure and syntax of the Dakota input file, but also must develop intermediate code that allows Dakota to set up and run a model, read outputs from the model, and calculate a response statistic from the outputs.
The CSDMS Dakota Interface, or Dakotathon, is a Python package that wraps and extends Dakota’s file-based user interface. It simplifies the process of configuring and running a Dakota experiment, and it allows a Dakota experiment to be scripted. Dakotathon creates the Dakota input file and provides a generic analysis driver. Any model componentized in the CSDMS modeling framework automatically works with Dakotathon. Dakotathon has a plugin architecture, so models not wrapped into the CSDMS modeling framework can be accessed by Dakotathon by programmatically extending a template; an example is provided in the Dakotathon distribution.
For more information on Dakotathon, including links to its documentation and its source code repository, please see the Dakotathon wiki page.
Permafrost Benchmark System
The Permafrost Benchmark System (PBS) wraps the command-line ILAMB benchmarking software with a customized version of WMT, and adds tools for uploading CMIP5-compatible model outputs and benchmark datasets. The PBS allows users to access and run ILAMB remotely, without having to install software or data locally; a web browser on a desktop, laptop, or tablet computer is all that’s needed.
For more information on the PBS, including links to documentation and source code repositories, please see the PBS home page at https://permamodel.github.io/pbs.
If you're already set up with a login on the PBS,
jump right to it at https://csdms.colorado.edu/pbs.
